What is Data Acquisition in AI? Methods, Types & Uses
Published: 20 Sep 2025
Artificial intelligence (AI) is only as powerful as the data it learns from. According to Gartner, poor data quality is responsible for up to 80% of AI and machine learning project failures — showing that data isn’t just important, it’s mission-critical. The first step that determines whether an AI system succeeds or fails is data acquisition: the process of collecting raw information in a form that machines can analyze and learn from.
So, what exactly is data acquisition in AI, and why does it matter? In simple terms, it is the structured process of gathering, measuring, and importing data — whether that’s text, images, audio, sensor readings, or user interactions — so it can be transformed into training material for algorithms. Without this step, no chatbot can understand language, no self-driving car can recognize road signs, and no predictive model can forecast trends.
Table of Contents
What is Data Acquisition in AI?
At its core, data acquisition in AI refers to the process of collecting raw data from various sources so it can be used to train, validate, and improve machine learning models. This data may come in many forms — numbers, text, images, audio, video, or sensor readings — but the goal is always the same: to transform real-world information into a structured format that algorithms can learn from.
Think of it as the “fueling stage” of AI. Just as a car cannot run without fuel, AI cannot function without reliable data. Without proper data acquisition, algorithms remain theoretical models with no practical application.
The Process of Data Acquisition in AI

While the specifics vary depending on the project and domain, most AI data acquisition workflows follow these core steps:
Step 1. Identify Data Requirements
Before any data is collected, it’s essential to define what kind of data is needed. For example:
- An NLP model may need text and voice recordings.
- A computer vision model may need labeled images or video.
- A predictive model in finance may need historical transaction records.
Step 2. Source the Data
Data can be acquired from:
- Internal company databases.
- External APIs (e.g., social media, IoT devices).
- Public datasets (e.g., Kaggle, UCI ML Repository).
- Direct collection methods like surveys or sensors.
Step 3. Collect and Ingest the Data
This is where raw data is gathered and stored. Methods can be manual (data entry, surveys) or automated (web scraping, IoT pipelines, API integrations).
Step 4. Validate and Filter Data
Not all collected data is useful. This step ensures:
- Removing duplicates.
- Filtering irrelevant or noisy entries.
- Checking compliance with data privacy laws (GDPR, HIPAA).
Step 5. Store in Usable Format
Finally, data must be stored in a structured, accessible way (databases, cloud storage, data lakes) to prepare it for preprocessing, labeling, and model training.
Data acquisition is not a one-time activity. In AI systems, especially those deployed in dynamic environments (e.g., fraud detection, autonomous driving), data acquisition is continuous — new data streams keep flowing in, ensuring models stay accurate and up-to-date.
Methods of Data Acquisition in AI
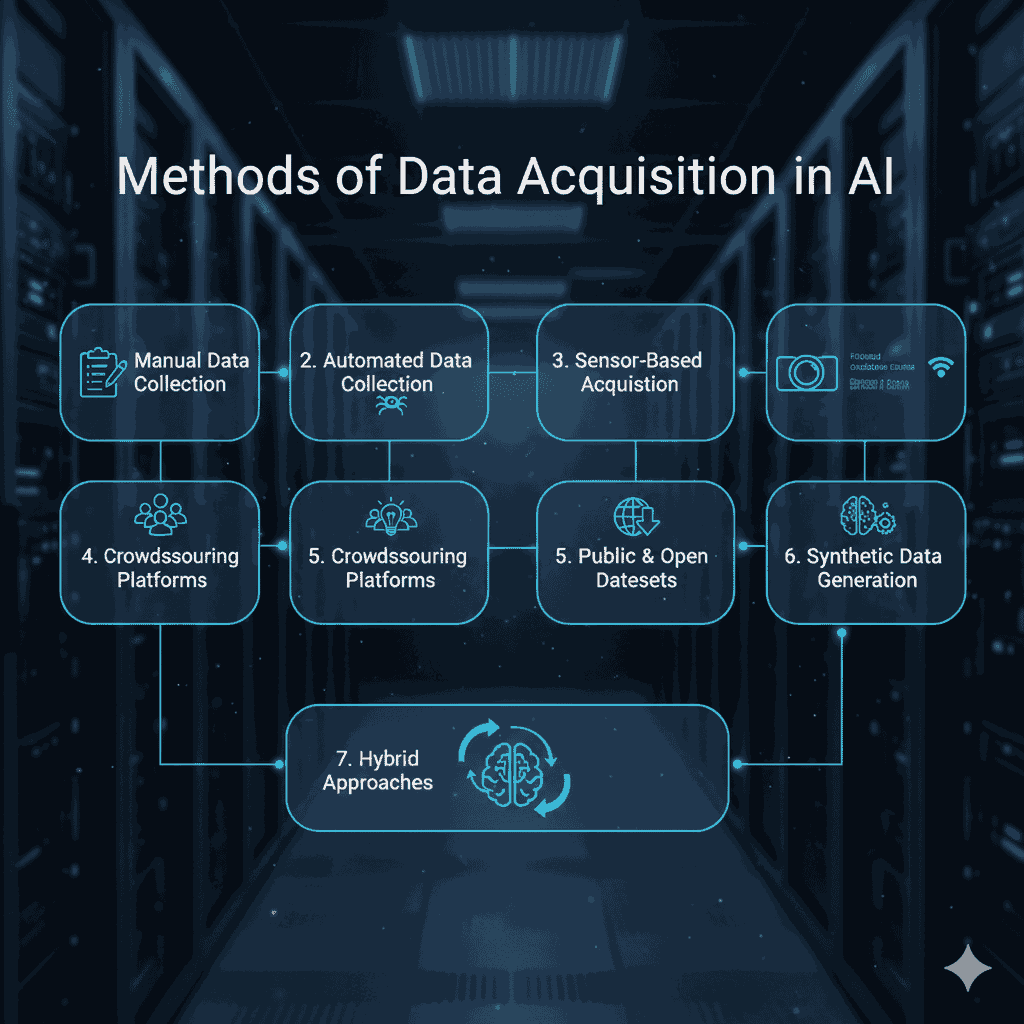
Data acquisition in AI isn’t a single technique — it’s a combination of methods tailored to the type of problem an AI system is trying to solve. Each method has its own strengths, limitations, and ideal use cases. Below are the main approaches:
1. Manual Data Collection
- Definition: Human-driven collection methods such as surveys, forms, or curated datasets.
- Use Cases: Small-scale projects, research studies, or when high-quality, domain-specific data is required.
- Pros: High accuracy and control over data quality.
- Cons: Time-consuming, expensive, and not scalable.
2. Automated Data Collection (Web Scraping & APIs)
- Definition: Using scripts, bots, or APIs to automatically gather large volumes of data from websites, platforms, or databases.
- Use Cases: Collecting product data for e-commerce, scraping news for NLP, or pulling structured datasets from APIs.
- Pros: Scalable, fast, cost-effective.
- Cons: May run into legal/ethical issues (e.g., scraping without permission); quality depends on source reliability.
3. Sensor-Based Acquisition (IoT & Robotics)
- Definition: Data gathered from hardware devices such as cameras, microphones, wearables, GPS trackers, and IoT sensors.
- Use Cases: Self-driving cars (LIDAR, radar, cameras), healthcare monitoring devices, smart homes.
- Pros: Real-time, dynamic, often high-resolution data.
- Cons: Requires specialized hardware, expensive to set up, massive storage needs.
4. Crowdsourcing Platforms
- Definition: Leveraging distributed human contributors (e.g., Amazon Mechanical Turk, Figure Eight) to generate or annotate data.
- Use Cases: Labeling images for computer vision, transcribing speech, or gathering subjective human feedback.
- Pros: Flexible, scalable, access to diverse human input.
- Cons: Quality can vary, requires quality control, ongoing costs.
5. Public & Open Datasets
- Definition: Using existing repositories of datasets made freely available by research institutions, companies, or governments.
- Examples: Kaggle, UCI Machine Learning Repository, ImageNet, Common Crawl.
- Pros: Cost-effective, good for prototyping and benchmarking.
- Cons: May not be specific enough for real-world applications; often already widely used by competitors.
6. Synthetic Data Generation
- Definition: Artificially generated data created using simulations, GANs (Generative Adversarial Networks), or other AI techniques.
- Use Cases: Training autonomous vehicles (simulated traffic environments), privacy-preserving AI, rare event prediction.
- Pros: Scalable, reduces privacy risks, fills gaps in rare scenarios.
- Cons: May lack real-world variability, risk of overfitting to synthetic patterns.
7. Hybrid Approaches
- Many real-world AI projects combine multiple methods:
- Example: A self-driving car system may use sensor-based data (cameras, LIDAR), crowdsourced labeling for images, and synthetic simulations for edge cases.
The choice of method depends on budget, scalability, data type, and compliance requirements. In practice, AI companies almost always use a mix of methods to ensure both quality and quantity.
Types of Data Used in AI

AI systems thrive on diverse forms of data. The type of data acquired directly influences the design of the model, the training process, and the quality of outputs. Below are the major categories of data used in AI:
1. Structured Data
- Definition: Data that is organized in tabular form (rows and columns) and stored in databases.
- Examples: Spreadsheets with sales numbers, customer demographics, financial transactions.
- Use Cases: Predictive analytics in finance, fraud detection, recommendation systems.
- Pros: Easy to store, query, and preprocess; works well with traditional ML algorithms.
- Cons: Limited in scope compared to unstructured data; doesn’t capture rich real-world context.
2. Unstructured Data
- Definition: Data without a predefined structure, often text-heavy or multimedia.
- Examples: Emails, social media posts, PDFs, images, audio, videos.
- Use Cases: Sentiment analysis, natural language processing (NLP), image recognition.
- Pros: Represents the majority of real-world data (over 80% of enterprise data is unstructured).
- Cons: Harder to process; requires specialized AI techniques like deep learning.
3. Semi-Structured Data
- Definition: Data that does not fit into strict tables but has some organizational tags.
- Examples: JSON, XML files, log files.
- Use Cases: API responses, system logs for anomaly detection, IoT data feeds.
- Pros: More flexible than structured data; easier to parse than raw unstructured data.
- Cons: Still requires significant preprocessing before use.
4. Text Data
- Definition: Written or spoken words in natural language.
- Examples: Chat transcripts, customer support tickets, research articles.
- Use Cases: Chatbots, translation systems, summarization tools.
- Pros: Rich source for NLP; widely available.
- Cons: Ambiguity and context issues in natural language; requires labeling.
5. Image Data
- Definition: Visual data captured via cameras or generated digitally.
- Examples: Photographs, X-rays, satellite images.
- Use Cases: Computer vision, medical imaging, facial recognition.
- Pros: Enables AI to “see” the world; critical in healthcare and robotics.
- Cons: Requires large datasets and heavy computing resources.
6. Audio Data
- Definition: Sound waves converted into digital signals.
- Examples: Voice commands, call center recordings, music samples.
- Use Cases: Voice assistants (Siri, Alexa), emotion detection, audio classification.
- Pros: Essential for speech recognition and audio AI.
- Cons: Quality issues like background noise can reduce accuracy.
7. Sensor & IoT Data
- Definition: Continuous real-time data streams from connected devices.
- Examples: Temperature sensors, GPS, wearable fitness trackers, industrial IoT sensors.
- Use Cases: Smart homes, predictive maintenance, autonomous vehicles.
- Pros: Real-time, high-frequency data improves responsiveness.
- Cons: Can overwhelm systems with volume; requires robust pipelines and storage.
Modern AI rarely depends on a single type of data. For example, autonomous vehicles combine image data (cameras), sensor data (LIDAR, radar), and text/audio data (navigation commands). The multi-modal approach makes AI systems more resilient and accurate.
Challenges in Data Acquisition for AI
Acquiring data for AI sounds straightforward, but in reality it’s one of the biggest obstacles to building reliable, ethical, and scalable machine learning systems. Below are the key challenges that organizations and researchers face:
1. Data Bias
- Definition: Bias occurs when the collected data does not accurately represent the real-world population or environment.
- Example: A facial recognition dataset trained mostly on lighter-skinned faces can lead to poor accuracy for darker-skinned individuals.
- Impact: Biased data leads to biased predictions, reinforcing discrimination and eroding trust.
- Solution: Ensure diversity in datasets, use balanced sampling, and continuously audit AI outcomes.
2. Data Quality & Noise
- Definition: Noise refers to irrelevant or incorrect entries in a dataset. Low-quality data includes missing fields, duplicates, or inconsistent formats.
- Example: Sensor data in autonomous cars may include false readings caused by weather conditions (fog, rain).
- Impact: Poor quality data reduces model accuracy, increases errors, and demands heavy preprocessing.
- Solution: Employ robust data cleaning, filtering, and validation techniques.
3. Missing or Incomplete Data
- Definition: When important parts of the dataset are unavailable or underrepresented.
- Example: Medical AI models may lack patient data for rare diseases, making it hard to predict outcomes accurately.
- Impact: Models trained on incomplete data struggle to generalize.
- Solution: Use imputation techniques, collect additional samples, or apply synthetic data generation to fill gaps.
4. High Costs of Data Acquisition
- Definition: Collecting, storing, and managing large-scale datasets requires significant financial and technical investment.
- Example: Self-driving car projects often spend millions to gather millions of miles of labeled driving data.
- Impact: Costs can be a barrier for startups and smaller research teams.
- Solution: Combine public datasets with smaller proprietary collections; use cost-efficient synthetic or simulated data.
5. Privacy & Compliance Issues
- Definition: Collecting personal or sensitive data must comply with strict privacy regulations (GDPR, HIPAA, CCPA).
- Example: Healthcare data often contains personally identifiable information (PII) that must be anonymized.
- Impact: Legal risks, fines, and loss of user trust if mishandled.
- Solution: Anonymize data, apply differential privacy techniques, obtain user consent.
6. Scalability & Storage Problems
- Definition: As AI models demand more data, organizations struggle with the volume, velocity, and variety of incoming data.
- Example: IoT networks may generate terabytes of data daily, overwhelming storage systems.
- Impact: Slows down training, increases costs, and complicates management.
- Solution: Use cloud-based storage, edge computing, and efficient data pipelines.
Challenges in data acquisition are not just technical — they include ethical, financial, and societal dimensions. Solving them requires a balance between quantity, quality, diversity, and compliance.
Tools & Frameworks for Data Acquisition in AI
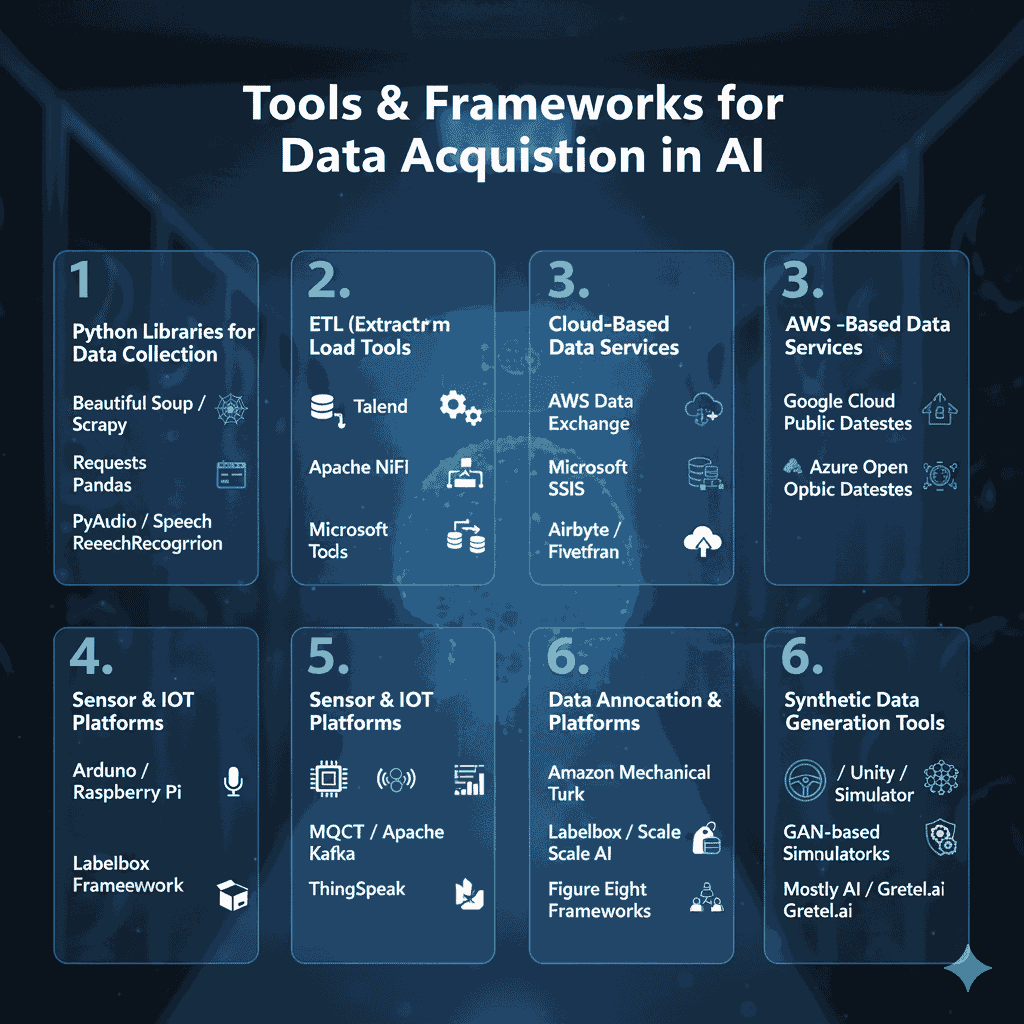
Efficient data acquisition doesn’t just depend on methods — it also requires the right tools and frameworks to collect, process, and manage large volumes of information. Below are some of the most commonly used solutions across industries:
1. Python Libraries for Data Collection
Python is the backbone of AI, and its ecosystem provides powerful libraries for data acquisition:
- BeautifulSoup / Scrapy → For web scraping and extracting structured data from websites.
- Requests → For pulling data from APIs.
- Pandas → For ingesting, cleaning, and structuring data from CSV, Excel, SQL, and more.
- PyAudio / SpeechRecognition → For audio data capture and processing.
2. ETL (Extract, Transform, Load) Tools
ETL platforms help automate the process of moving data from raw sources into usable formats:
- Apache NiFi → Open-source tool for automating data flows between systems.
- Talend → Data integration platform widely used for preparing AI training datasets.
- Microsoft SSIS (SQL Server Integration Services) → Enterprise-level ETL for structured data.
- Airbyte / Fivetran → Modern cloud-based ETL solutions with pre-built connectors.
3. Cloud-Based Data Services
Major cloud providers offer specialized services for AI-ready datasets:
- AWS Data Exchange → Marketplace for third-party datasets.
- Google Cloud Public Datasets → Free, high-quality datasets for ML training.
- Azure Open Datasets → Curated, open data for AI development.
4. Sensor & IoT Platforms
For projects involving real-time sensor data:
- Arduino / Raspberry Pi → Hardware platforms to collect IoT data.
- MQTT / Apache Kafka → Messaging frameworks to handle streaming IoT data.
- ThingSpeak → IoT analytics platform for aggregating sensor data.
5. Data Annotation & Crowdsourcing Platforms
Annotation is often integrated into acquisition when raw data must be labeled:
- Amazon Mechanical Turk (MTurk) → Human-powered data labeling and collection at scale.
- Labelbox / Scale AI → Platforms specializing in AI training dataset creation.
- Figure Eight (Appen) → Crowdsourcing platform for annotation and dataset enrichment.
6. Synthetic Data Generation Tools
When real-world data is scarce or sensitive:
- Unity / CARLA Simulator → For creating synthetic driving environments.
- GAN-based Frameworks (TensorFlow, PyTorch) → Generate artificial images, audio, or text.
- Mostly AI / Gretel.ai → Synthetic data startups focused on privacy-preserving data generation.
Choosing the right tool depends on the scale, type of data, and compliance needs. In practice, teams often combine Python libraries for scraping/APIs, ETL tools for transformation, and cloud services for scalable storage.
Applications and Use Cases of Data Acquisition in AI
Data acquisition isn’t just a technical process — it’s the foundation that enables real-world AI applications across industries. The way data is collected determines how effective an AI system will be in solving domain-specific problems. Below are the key industries where data acquisition plays a transformative role:
1. Healthcare & Medicine
- Examples of Data: Electronic health records (EHR), medical imaging (X-rays, MRIs), wearable device data.
- Use Cases:
- Early disease detection (e.g., AI models trained on imaging data for cancer diagnosis).
- Predictive analytics for patient risk assessment.
- Personalized treatment plans using patient history.
- Early disease detection (e.g., AI models trained on imaging data for cancer diagnosis).
- Challenge Highlight: Strict compliance requirements (HIPAA, GDPR) and patient data privacy.
2. Finance & Banking
- Examples of Data: Transaction records, market feeds, customer behavior logs.
- Use Cases:
- Fraud detection systems analyzing millions of transactions in real-time.
- Algorithmic trading powered by high-frequency financial data.
- Credit scoring based on alternative data sources.
- Fraud detection systems analyzing millions of transactions in real-time.
- Challenge Highlight: Noise in data streams and the cost of acquiring accurate, up-to-the-second information.
3. Robotics & Autonomous Systems
- Examples of Data: Sensor data (LIDAR, radar, GPS), video feeds, motion tracking.
- Use Cases:
- Self-driving cars navigating with real-time multi-sensor data.
- Industrial robots learning from production-line sensor inputs.
- Drones mapping terrain with camera and GPS data.
- Self-driving cars navigating with real-time multi-sensor data.
- Challenge Highlight: The massive volume of real-time data requires ultra-low-latency pipelines.
4. Natural Language Processing (NLP) & Conversational AI
- Examples of Data: Text corpora, customer support chats, voice recordings.
- Use Cases:
- Chatbots and virtual assistants (Siri, Alexa, ChatGPT).
- Sentiment analysis for brand monitoring.
- Machine translation systems.
- Chatbots and virtual assistants (Siri, Alexa, ChatGPT).
- Challenge Highlight: Language diversity, ambiguity, and cultural nuances make data acquisition complex.
5. Retail & E-commerce
- Examples of Data: Customer browsing behavior, purchase history, product reviews.
- Use Cases:
- Recommendation engines (Amazon, Netflix).
- Dynamic pricing models.
- Inventory management optimization.
- Recommendation engines (Amazon, Netflix).
- Challenge Highlight: Balancing personalization with user privacy.
Across industries, the quality and relevance of acquired data directly determine the accuracy and trustworthiness of AI applications. Poor data acquisition = poor AI outcomes, regardless of how advanced the algorithms are.
Data Acquisition vs Related Concepts
Although data acquisition is a core step in AI development, it’s often confused with other processes like preprocessing, labeling, or data generation. Here’s how they differ:
1. Data Acquisition vs Data Preprocessing
- Data Acquisition → The act of collecting raw data from various sources (sensors, APIs, surveys, scraping, datasets).
- Data Preprocessing → The process of cleaning, normalizing, and structuring raw data so it’s ready for model training.
- Key Difference: Acquisition is about collecting data; preprocessing is about refining it.
- Example: Collecting thousands of raw images = acquisition. Removing duplicates, resizing, and converting them into usable formats = preprocessing.
2. Data Acquisition vs Data Labeling
- Data Acquisition → Ingesting raw, unlabeled information.
- Data Labeling → Adding annotations, tags, or metadata that make the data understandable to AI models.
- Key Difference: Acquisition gives you the data; labeling gives the data meaning.
- Example: Gathering speech recordings = acquisition. Tagging transcripts with “positive” or “negative sentiment” = labeling.
3. Data Acquisition vs Data Generation
- Data Acquisition → Collecting real-world data from natural sources.
- Data Generation → Creating synthetic or simulated data artificially, often with AI techniques like GANs.
- Key Difference: Acquisition deals with real-world inputs; generation creates artificial data to fill gaps or expand datasets.
- Example: Downloading a medical dataset from a hospital = acquisition. Using a simulator to create synthetic CT scans = generation.
Quick Comparison Table
| Process | What It Does | Example Use Case |
| Data Acquisition | Collect raw data from real sources | Gathering customer purchase history |
| Data Preprocessing | Clean & structure the data for training | Normalizing transaction values |
| Data Labeling | Add tags/annotations for ML understanding | Labeling fraud vs non-fraud transactions |
| Data Generation | Create synthetic/artificial datasets | Generating rare disease cases for medical AI |
Ethics and Privacy in Data Acquisition
Data is the foundation of AI, but acquiring it comes with serious ethical responsibilities and legal obligations. Mishandling data not only risks fines and lawsuits but also undermines user trust and damages the credibility of AI systems. Below are the key considerations:
1. Privacy Regulations
- GDPR (General Data Protection Regulation – EU): Requires informed consent before collecting personal data, limits storage duration, and enforces the “right to be forgotten.”
- HIPAA (Health Insurance Portability and Accountability Act – US): Governs the collection and storage of patient health data.
- CCPA (California Consumer Privacy Act – US): Gives consumers control over how businesses collect and use their personal data.
- Key Takeaway: Compliance with these regulations is non-negotiable when acquiring sensitive or personal data.
2. Informed Consent
- Definition: Users should know how their data will be collected, stored, and used.
- Example: Mobile apps must disclose whether they’re collecting location or microphone data.
- Ethical Principle: Transparency fosters trust and prevents exploitation.
3. Data Anonymization & De-identification
- Why: To protect individual identities while still enabling AI training.
- Techniques: Removing identifiers (names, emails), applying differential privacy, aggregating datasets.
- Example: Healthcare data can be anonymized so researchers use it without exposing patient identities.
4. Fairness and Bias Reduction
- Ethical Issue: If acquired data is skewed, AI outputs can reinforce discrimination.
- Example: Biased hiring algorithms trained on historical data may favor certain demographics.
- Solution: Diverse data sources, fairness audits, and algorithmic transparency.
5. Responsible AI Practices
- Principles to Follow:
- Transparency: Explain how data was acquired.
- Accountability: Hold organizations responsible for misuse.
- Security: Protect data against breaches and misuse.
- Transparency: Explain how data was acquired.
- Industry Movement: Major tech companies and institutions now publish AI ethics guidelines to ensure responsible data handling.
Ethics in data acquisition isn’t just about following the law. It’s about ensuring that AI systems are fair, transparent, and trustworthy. The best-performing AI systems are those that balance innovation with responsibility.
The Future of Data Acquisition in AI
As AI systems become more advanced and data-hungry, traditional acquisition methods are reaching their limits. The future of data acquisition is being shaped by emerging technologies, automation, and stricter ethical standards. Here are the key trends to watch:
1. Synthetic Data on the Rise
- Definition: Artificially created data using simulations or AI models (e.g., GANs).
- Why It Matters: Helps fill gaps where real-world data is scarce, sensitive, or expensive.
- Example: Autonomous vehicle companies use simulated driving environments to generate millions of rare traffic scenarios.
- Future Outlook: By 2030, Gartner predicts that synthetic data will outpace real-world data in AI training datasets.
2. Automated Data Acquisition Pipelines
- Trend: End-to-end automation using AI agents, robotic process automation (RPA), and APIs to acquire and validate data continuously.
- Benefit: Reduces manual effort, scales acquisition, and ensures fresh, real-time datasets.
- Example: Financial AI systems automatically ingest live trading data streams for predictive analytics.
3. Federated Learning & Privacy-Preserving Acquisition
- Definition: A decentralized approach where AI models train directly on local devices without moving data to central servers.
- Example: Google’s Gboard keyboard learns from user typing behavior without transferring private messages to the cloud.
- Future Outlook: Privacy-first acquisition will become standard, especially under stricter regulations like GDPR.
4. Multimodal Data Acquisition
- Trend: Collecting multiple types of data simultaneously (text, audio, video, sensor) for richer AI training.
- Example: Smart home systems combining voice commands (audio), motion sensors, and video feeds for better automation.
- Future Outlook: Multimodal data will power next-generation AI models that think more like humans.
5. Edge & Real-Time Data Collection
- Definition: Collecting and processing data directly on edge devices (phones, IoT sensors, wearables) instead of central servers.
- Benefit: Faster decision-making, reduced latency, improved privacy.
- Example: Wearable health trackers acquiring real-time vitals and providing instant feedback.
- Future Outlook: Edge computing will dominate industries like healthcare, autonomous vehicles, and robotics.
The future of data acquisition in AI is about scalability, privacy, and realism. Organizations that embrace synthetic data, automation, and privacy-first approaches will have a competitive edge in building reliable, ethical AI systems.
Conclusion
Data acquisition in AI is more than just the first step in building intelligent systems — it is the foundation that determines whether an AI model succeeds or fails. From collecting structured and unstructured data to tackling challenges like bias, cost, and compliance, every stage of acquisition shapes the accuracy, fairness, and reliability of AI outcomes.
We’ve seen how different methods (manual, automated, IoT sensors, synthetic generation), diverse data types (text, images, audio, sensor streams), and modern tools and frameworks all play a role in ensuring AI has the right fuel to learn. We’ve also explored how acquisition differs from preprocessing, labeling, and generation, and why ethics and privacy must remain central in every strategy.
Looking ahead, the future of data acquisition will be defined by synthetic data, automation, multimodal collection, and privacy-first approaches like federated learning. Organizations that embrace these trends while maintaining ethical responsibility will build AI systems that are not only powerful but also trusted, transparent, and human-centered.
FAQs
What is data acquisition in AI?
Data acquisition in AI is the process of collecting raw information (text, images, audio, sensor data, etc.) from various sources so it can be used to train machine learning models.
Why is data acquisition important in AI?
Because the accuracy and reliability of AI systems depend directly on the quality and diversity of the data they are trained on. Poor acquisition = poor AI outcomes.
What are the main methods of data acquisition?
Methods include manual collection, automated scraping, APIs, IoT sensors, crowdsourcing, open datasets, and synthetic data generation.
How does data acquisition differ from data preprocessing?
Acquisition is about collecting raw data, while preprocessing is about cleaning and structuring it for training.
What are the biggest challenges in data acquisition?
Bias, noise, incomplete datasets, high costs, privacy regulations, and scalability issues.
What’s the future of data acquisition in AI?
Expect more use of synthetic data, privacy-preserving techniques (like federated learning), and edge-based real-time collection.






- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
