What is Multimodal RAG?
Published: 5 Feb 2026
Multimodal retrieval augmented generation (multimodal RAG) is an advanced Artificial Intelligence (AI) system that enhances traditional RAG by incorporating different types of data, such as text, images, tables, audio, and video. Unlike traditional RAG, multimodal RAG can process and retrieve information from diverse data modalities and generate contextually accurate and relevant responses using generative ai models like OpenAI’s GPT-4 or Google’s Gemini.
Multimodal RAG utilizes modality encoders, neural network components that transform raw data from various modalities. These encoders map representations to a shared embedding space, enabling cross-modal retrieval and grounding the generative model’s response in multimodal evidence. This approach is valuable for applications like visual question answering and multimedia search engines, improving accuracy and context awareness by combining insights from different modalities.
The main benefits of multimodal RAG include enhanced accuracy, improved context awareness, and the ability to reason between inputs to generate precise and grounded responses. It finds applications in visual question answering, multimedia search engines, and other areas where understanding diverse data modalities is crucial.
The main components of a multimodal RAG system include modality encoders, a vector database for storing multimodal embeddings, and a multimodal Large Language Model (LLM) for response generation. The system processes multimodal data, retrieves relevant information, and generates outputs grounded in multimodal evidence, reducing the risk of hallucination.
Table of Contents
How Multimodal RAG Works
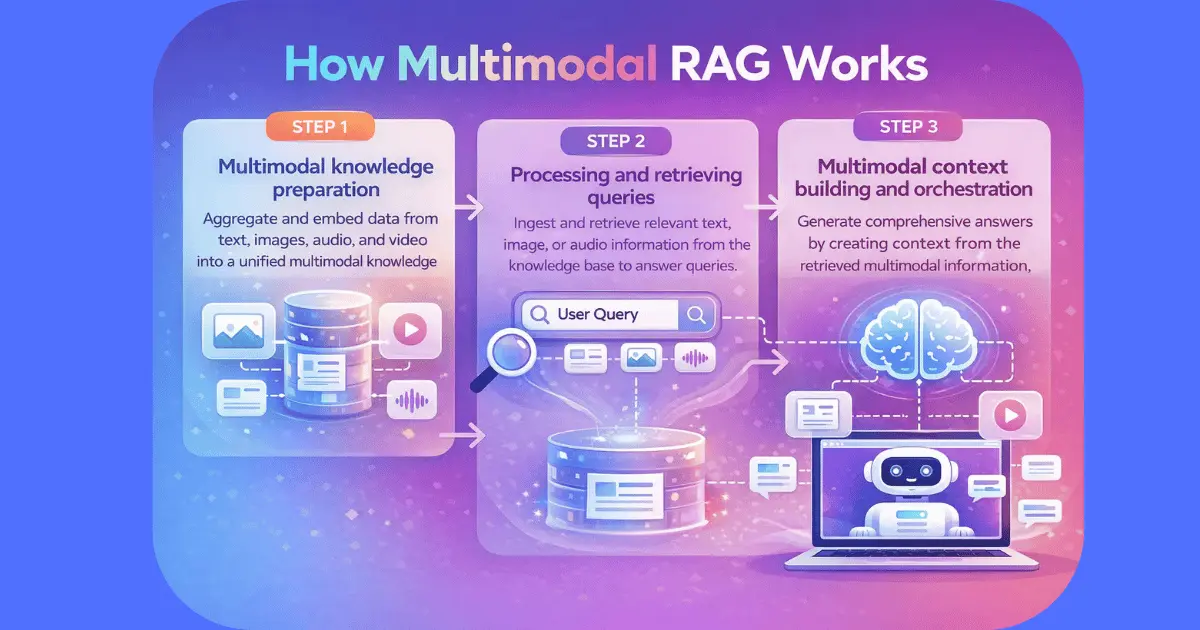
Multimodal RAG systems generally follow an end-to-end workflow, often implemented through APIs for easy integration or orchestrated by AI agents for autonomous retrieval and response generation. This workflow can be broken down into three key steps: multimodal knowledge preparation, query processing and retrieval, and multimodal context building and orchestration.
Step 1: Multimodal knowledge preparation
The first step involves multimodal knowledge preparation. Data from various sources is parsed and encoded into embeddings using appropriate modality encoders. For example, CNNs (convolutional neural networks) can be used for images, transformers for text, and wav2vec for audio. These embeddings are stored in a shared or aligned feature space. This alignment is often achieved through contrastive learning, where paired data (e.g., image-caption, audio-transcript) is optimized to lie close in the embedding space, enabling cross-modal semantic matching. Image captioning and image summaries generated by vision language models can also enrich retrieval performance by providing textual descriptions of visual content. Importantly, all original modalities are preserved to retain nontextual detail.
Step 2: Processing and retrieving queries
The second step processes and retrieves queries. The user’s query is converted into an embedding and evaluated against the stored multimodal embeddings using a similarity search. The original modalities are saved to preserve relevant information, enabling any-to-any retrieval, where a text query can fetch an image, an image can fetch related text, and so on. Vector databases like Pinecone, which can store billions of multimodal embeddings, offer effective, low-latency nearest-neighbor search at scale, forming the foundation of multimodal information retrieval.
Step 3: Multimodal context building and orchestration
The third step involves multimodal context building, where the retrieved results are prepared for generation. Some systems use early fusion by converting everything into text before generation, while others use late fusion, where different modalities remain separate and the generator attends to them directly. Frameworks like LangChain can be used to orchestrate retrieval, fusion, and generation pipelines efficiently. Graphs can also represent relationships between multimodal entities, helping the system better understand connections across data.
Applications of Multimodal RAG
Multimodal RAG systems have become powerful tools in various applications, demonstrating improved performance by utilizing diverse data types. They are particularly useful in industrial applications and open-domain question answering.
A study on industrial applications prototyped a multimodal RAG system using 100 questions and answers from technical manuals requiring understanding of both text and images. The system was tested in three configurations: text-only RAG, image-only RAG, and multimodal RAG. Results indicated that multimodal data captured by text and image data achieved higher performance than either a text-only or image-only resource. GPT-4V performed better than LLaVA in accurately synthesizing multimodal content, enabling the system to parse diagrams and instructions and provide more accurate and relevant answers due to the more clearly defined context.
Another study introduced MuRAG (multimodal retrieval augmented transformer) for open-domain question answering over both image and text. MuRAG evaluates an external multimodal memory to retrieve relevant images and texts to augment language generation. The model combines a pretrained T5 model and a pretrained vision transformer (ViT) model to embed multimodal data embeddings in a memory bank, leveraging a joint contrastive and generative training objective. In large-scale experiments on WebQA and MultimodalQA, MuRAG outperformed existing baselines by 10–20% in accuracy.
Key challenges of Multimodal RAG
Despite its benefits, multimodal RAG presents several challenges:
- Computational complexity: Integrating a multimodality approach requires heavy computation for training and inference, leading to slower inference times and increased costs at a large scale.
- Data alignment and synchronization issues: Ensuring that the embedding spaces align with the most relevant pieces across different modality types is a challenge. Misalignment during training or retrieval can lead to semantic errors and performance degradation.
- Evaluation metrics for multimodal: Current benchmarks are primarily text-based and do not include multimodal grounding and reasoning aspects, requiring further research to develop robust evaluation metrics for multimodal RAG.
- Data availability and quality: High-quality multimodal datasets within specific domains are scarce and costly to curate, limiting the training of high-quality generalizable multimodal RAG systems.
- Hallucination and faithfulness: Multimodal LLMs are grounded on retrieved data, but hallucination problems persist. Models may overgeneralize when modalities conflict, making reliable grounding a challenge.
Why is multimodality hard?
Working with diverse data modalities presents unique challenges. Enterprise data is often spread across multiple modalities, such as images, PDFs, tables, charts, and diagrams. Addressing this modality spread requires careful consideration of the challenges specific to each modality and how to manage information across modalities.
Each modality has its own challenges
Each modality presents its own unique challenges. For example, images can range from general imagery to information-dense charts and diagrams. A multimodal RAG pipeline must capture and address these nuances to effectively embed information. Reports and documentations may contain information-dense images, like charts and diagrams, which have many points of interest and additional context that can be derived from the image.
How do you manage information across modalities?
Representing information across different modalities is crucial. For instance, when working with a document, the semantic representation of a chart must align with the semantic representation of the text discussing the same chart. Ensuring this alignment is essential for effective cross-modal understanding and reasoning.
Approaches for multimodal retrieval
There are several main approaches to building multimodal RAG pipelines, including embedding all modalities into the same vector space, grounding all modalities into one primary modality, and having separate stores for different modalities.
Embed all modalities into the same vector space
This approach uses models like CLIP (Contrastive Language-Image Pretraining) to encode both text and images in a common vector space. This allows the use of the same text-only RAG infrastructure, with the embedding model swapped to accommodate another modality. For generation, the LLM is replaced with a multimodal LLM (MLLM) for question answering. This simplifies the pipeline, requiring only the embedding model to be changed. The tradeoff is the need for a model that can effectively embed different types of images and text and capture intricacies like text in images and complex tables.
Ground all modalities into one primary modality
This involves selecting a primary modality based on the application’s focus and grounding all other modalities in that primary modality. For example, in a text-based Q&A application over PDFs, text is processed normally, but images are converted into text descriptions and metadata during preprocessing. The images are stored for later use. During inference, retrieval works primarily off the text description and metadata for the images, and the answer is generated with a mix of LLMs and MLLMs, depending on the type of image retrieved. This approach benefits from the metadata generated from the information-rich image, which is helpful in answering objective questions. However, it incurs preprocessing costs and may lose some nuance from the image.
Have separate stores for different modalities
The rank-rerank approach involves having separate stores for different modalities, querying them all to retrieve top-N chunks, and then using a dedicated multimodal re-ranker to provide the most relevant chunks. This simplifies the modeling process, eliminating the need to align one model to work with multiple modalities. However, it adds complexity in the form of a re-ranker to arrange the now top-M*N chunks (N each from M modalities).
Multimodal models for generation
LLMs are designed to understand, interpret, and generate text-based information, performing tasks such as text generation, summarization, and question-answering. MLLMs, on the other hand, can perceive more than textual data, handling modalities like images, audio, and video. They combine these different data types to create a more comprehensive interpretation of the information, improving the accuracy and robustness of predictions. These models can perform tasks such as visual language understanding and generation, multimodal dialogue, image captioning, and visual question answering (VQA). One popular subtype of MLLMs is Pix2Struct, a pretrained image-to-text model that enables semantic understanding of visual input with its novel pretraining strategy, generating structured information extracted from the image.
Building a pipeline for multimodal RAG
Building a pipeline for multimodal RAG involves several steps, including interpreting multimodal data, creating a vector database, and extending the RAG pipeline to address complex user questions and generate multimodal responses.
Interpreting multimodal data and creating a vector database
The first step for building a RAG application is to preprocess the data and store it as vectors in a vector store for retrieval. With images present, a generic RAG preprocessing workflow involves several key steps. For instance, consider technical posts containing complex images with charts and graphs, rich text, and tabular data.
Separate images and text
The initial goal is to ground images to the text modality. Start by extracting and cleaning your data to separate images and text. Then, tackle these two modalities to store them in the vector store.
Classify images using an MLLM based on the image types
Image descriptions generated by an MLLM can be used to classify images into categories, such as whether or not they are graphs. Based on the classification, use DePlot for images containing graphs to generate a linearized tabular text. Summaries of the linearized text can be stored as chunks in the vector store with the outputs from customized MLLMs as metadata, which can be used during inference.
Embed text in PDFs
Explore various text-splitting techniques based on the data. For simplicity, store each paragraph as a chunk.
Talking to your vector database
When a user prompts the system with a question, a simple RAG pipeline converts the question into an embedding and performs a semantic search to retrieve relevant chunks of information. Considering that retrieved chunks also come from images, additional steps are taken before sending the chunks to the LLM for generating the final response. If the chunk was extracted from an image, an MLLM takes the image along with the user question as input to generate an answer, performing a VQA task. If the chunk is extracted from a chart or plot, the linearized table stored as metadata is appended as context to the LLM. Chunks from plain text are used as is.
Extending the RAG pipeline
To further develop multimodal RAG technology and extend its capabilities, research is needed in several areas.
Addressing user questions that include different modalities
Consider user questions consisting of an image containing a graph and a list of questions. Changes in the pipeline are required to accommodate this type of multimodal request.
Multimodal responses
Text-based answers are provided with citations representing other modalities. Multimodal responses can be further extended to generate images upon request, such as a stacked bar chart.
Multimodal agents
Solving complex questions or tasks requires planning, specialized tools, and ingestion engines.
Summary
Multimodal RAG represents a significant advancement in AI, enhancing traditional RAG by incorporating diverse data modalities like text, images, audio, and video. By using modality encoders to map representations to a shared embedding space, multimodal RAG enables cross-modal retrieval and generates contextually accurate responses. This technology finds applications in areas like visual question answering and multimedia search engines, improving accuracy and context awareness. While challenges such as computational complexity and data alignment persist, ongoing advancements in multimodal models and increasing demand for RAG-powered tools and services suggest a promising future for multimodal RAG in generative AI applications. Multimodal RAG can be a critical technology for knowledge-intensive applications, resulting in AI systems that are able to reason more like humans by combining vision, language, audio, and structured data.
FAQs
What is a key difference between text based RAG and multi modal RAG?
Text based RAG relies only on written documents to retrieve information and support response generation. Multi modal RAG goes further by retrieving and combining knowledge from text, images, audio, and video, which allows the system to understand richer context and provide more accurate and meaningful answers.
What is a multi modal model?
A multi modal model is an artificial intelligence system that can understand and work with more than one type of data at the same time. It can process text, images, audio, and video together and use the combined information to generate responses that reflect a deeper understanding of the input.
What is an example of a multimodal system?
A common example of a multimodal system is an AI assistant that can look at an image, read related documents, understand spoken questions, and then respond in natural language. This kind of system uses multiple data sources to form a single, coherent output.
What is multi modal retrieval?
Multi-modal retrieval is the process of searching for and retrieving relevant information from different types of data using one query. It allows an AI system to gather text, images, audio, or video together so the final response is based on a more complete and well-connected context.
Is ChatGPT a multimodal model?
Yes, ChatGPT is a multimodal model.
It can understand and work with multiple types of input, including text and images, and can generate text based on that combined understanding. In some setups, it can also reason over visual content such as charts, screenshots, or photos, making its responses more context aware than text only models.






- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
